Today I’ve put out the first release iteration of my personal bookshelf web application. My New Year’s Resolution for 2010 was to:
- Read more
- Buy no books
So far things are right on track, and I’ve been able to stick to that goal. One method that’s helped me accomplish this is to keep a ‘digital bookshelf’ on Librarything. Having a real bookshelf with all the books that you read is a simple way to remember what you’ve read, but it’s not a very practical or conservative method (in terms of space and cost). So about 2 years ago I started keeping a list of books I read on Librarything. I can’t speak more highly of some of the wonderful tools that Librarything offers. It has tools that help you discover new books related to what you like and connect with other book enthusiasts. The ‘digital bookshelf’ feature is where you can keep a list of the books you read, tag them and rate them. I’m not a big fan of the way Librarything presents this book collection. I wanted something more personal, less cookie cutter, and more geared at the way I read. Librarything’s interface also gets to be way too cluttered and confusing, when all I really want to do is keep track of what I read. Plus, being able to ‘own my own data’ is important to me.
With that in mind, I have just launched ‘Blake’s Bookshelf (Words I Read)’. You can check it out HERE.
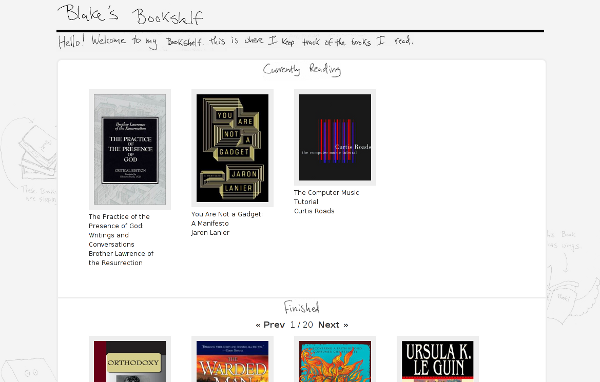
design goals
- Simple to use
- ‘Human’ feel
- 3 categories for my books: Currently Reading, Finished, To-Read Pile
- Easy to add new books and switch them around in the categories
technical details
In the current iteration, Blake’s Bookshelf leverages the following technology stack:
- Ruby - application and scripting programming language
- Sinatra - ruby web framework used for serving the front page and web service calls
- Heroku - used for testing the application in a staging environment
- jQuery - javascript library to do dynamic visual elements as well as web service calls
- JSON - web services return json for dynamic content
- YAML - book data is stored in YAML format
- Capistrano - automated application deployment
- Thin - application http server
- Nginx - public facing web server that proxies to thin
amazon ecs
I leverage the amazon-ecs Ruby library to poll Amazon for book data. My script takes in an ISBN and spits out the YAML data. It also pulls down the cover image from amazon and resizes using the Image Science ruby library and places it in the appropriate directory.
future
If the dataset gets too unwieldy to deal with (or I have some feature that needs some advanced querying), I may migrate the YAML data into a MongoDB database. I have a few other minor features in mind that may add some subtle value, but nothing is definite.
Check it out and enjoy!