If you’re looking for a Rust based Vmm alternative to Firecracker,
I’d check out Cloud Hypervisor. Cloud Hypervisor ended up hitting that sweet spot for me
in many places where Firecracker is chasing different outcomes.
Both projects share so many things to love:
- Entirely Rust based, sharing many quality crates from the rust-vmm project.
- Built on top of the Linux KVM hypervisor
- Good virtio device support (disks, network interfaces, etc.)
- Simple Vmm Http API
In contrast to Firecracker, Cloud Hypervisor directly targets long-lived, stateful VMs (but can also slim down to ‘microvm’ territory),
and thus supports other features that Firecracker will most likely never add.
UEFI boot support
Unlike Firecracker, which only supports direct Linux boot, Cloud Hypervisor can boot a minimal UEFI firmware. This
gives your guest VM direct control of the kernel upgrade lifecycle from within the guest. It also allows running OS types other
than Linux. If you’re running long-lived stateful VMs that expect to manage their own kernel version upgrades over
time, then this is what you want. I’m no fan of the complexities of UEFI, but the realities are that if you want wide-spread
guest boot support (including Windows, etc.), having at least basic UEFI support is a good and useful thing.
Firecracker requires using Linux Direct Boot. This limits your
guest VMs to Linux only, and requires that the Vmm itself manage the kernel upgrade lifecycle of the guest VMs. Firecracker is optimizing
for something different than Cloud Hypervisor: Lightweight, short-lived VMs that are biased towards serverless function workloads (It
was built for Amazon’s Lambda after all). Cloud Hypervisor also supports Linux direct boot in addition to UEFI support.
Qcow2 disk images
Firecracker only ships with Raw disk image support. The biggest drawback I hit with raw disk images is that it requires
pre-allocating the entire guest disk, consuming valuable host disk capacity (or implementing other complex setups like device-mapper for overlay).
These pre-allocations also lead to extra byte copying when shuffling block devices around a host cluster.
Instead, Cloud Hypervisor has direct Qcow2 support. This gives us baked in support for thin-allocated disk images (saving over-allocation), as well as backing-file
support. You can have read-only overlay semantics for shared disk image lineage, snapshots, etc. No external device
mapper required.
For generating base images, it’s much easier to generate Qcow2 images with base a base OS install, and then at VM provisioning time,
issue a quick metadata operation to the Qcow2 file to resize the image for each provisioned guest.
Beyond Qcow2 disk images, I previously wrote an experimental implementation of network attached block devices for Firecracker.
While this quick and dirty experiment worked, Firecracker’s focus on short-lived VMs for serverless functions made me doubt whether network-attached storage code patches would be welcome upstream. I’d
love to push contributions back to Cloud Hypervisor that enable arbitrary block-device backend support.
Live migration
I haven’t gotten to plumb in live-migration yet, but this is something Firecracker is also unlikely to ever add, due to
its focus on short-lived VMs. I’m looking forward to implementing this one on my cluster control plane!
Not Amazon
Fundamentally, I’m just not comfortable making deep investments in a project that’s governed by Amazon. Amazon’s values don’t align well
with mine as of late, and I’d rather invest in tooling that doesn’t put more compute power in Jeff Bezos’ pocket.
To be sure: there are other hyperscalers involved in Cloud Hypervisor, but the diversity gives me more confidence. The last major release saw contributions
from technologists at Microsoft, Google, Meta, IBM, Tencent, and several more.
I’m much choosier about licenses and governance of open source projects I contribute to these days. Too many rug-pulls for comfort.
Give it a try
I was able to add Cloud Hypervisor support to my internal cloud control plane in about a day or so. It shares many of the broad
feature sets that Firecracker has, and then goes further.
If you’ve ever been intrigued by Firecracker, and are looking for an alternative whose mission isn’t so pigeon-holed into serverless, I’d
give Cloud Hypervisor a look!
NOTE: This is a longer explanation to a question I responded to on GitHub about dynamically adding listeners / services to Pingora.
I wanted to show the technique I’m using to dynamically manage Pingora LoadBalancer instances inside a general proxy / load balancer service I’m building. Pingora is a Rust based proxy library from Cloudflare that can be used to build high performance http load balancers and proxy services.
Pingora’s design prompts you to setup your process using a static Service graph that you build
during process startup. This similar to patterns found in Guava’s Service interface, for managing several logical asynchronous services inside a single process. You configure your various services (load balancers, proxy services, background health checks, etc), add them to a Server instance, and then start the Server which takes over the lifecycle of your services.
From Pingora’s getting started guide:
fn main() {
let mut server = Server::new(None).unwrap();
server.bootstrap();
let upstreams = LoadBalancer::try_from_iter(["1.1.1.1:443", "1.0.0.1:443"]).unwrap();
let mut lb = http_proxy_service(&server.configuration, LB(Arc::new(upstreams)));
lb.add_tcp("0.0.0.0:6188");
server.add_service(lb);
server.run_forever();
}
The Server struct normally does a lot of heavy lifting for you:
- Clean process startup / shutdown, including handling the correct
Service dependency ordering.
- Managing each Service’s tokio
Runtime. The Server instance creates an individual Runtime instance for each Service that it manages.
- Zero downtime listener socket handoff: The
Server handles handing off listener file descriptors over a unix socket to a new process to support zero downtime upgrades. This is very similar to how something like Envoy proxy does online hot restarts.
One major problem: After setting up services, the API to start the Server returns a Rust “Never type”.
Once your program hands off control to Server#run_forever, you’re never getting it back.
impl Server {
/// Start the server using Self::run and default RunArgs.
/// This function will block forever until the server needs to quit. So this would be the last function to call for this object.
/// Note: this function may fork the process for daemonization, so any additional threads created before this function will be lost to any service logic once this function is called.
pub fn run_forever(self) -> !
}
It’s quite easy to forgo the Server type entirely, easily use all the Pingora services, and retain full control of your process. This gives you the ability to dynamically start / stop
services (including LoadBalancer instances), or do whatever else you want. It’s on you to manage clean shutdown, and provision tokio runtimes. You lose out on some of the other built-ins like zero downtime hot restarts, but in my case, it’s worth it.
Starting a LoadBalancer without a Server is pretty straightforward:
fn make_load_balancer() -> GenBackgroundService<LoadBalancer<RoundRobin>> {
let backends = Backends::new(Box::new(ResourceDiscovery));
let mut load_balancer = LoadBalancer::from_backends(backends);
let health_check = TcpHealthCheck::new();
load_balancer.set_health_check(health_check);
load_balancer.health_check_frequency = Some(Duration::from_secs(5));
load_balancer.update_frequency = Some(Duration::from_secs(30));
let load_balancer_service = background_service("health_check", load_balancer);
load_balancer_service
}
fn main() -> Result<(), anyhow::Error> {
// Manage our own tokio Runtime
let runtime = tokio::runtime::Runtime::new()
.expect("Could not start tokio runtime");
// Create a Vec of tokio task handles, so we can wait for
// them to finish during process shutdown
let mut tasks = Vec::new();
// Each service watches this common channel to trigger clean shutdown.
let (shutdown_tx, shutdown_rx) = tokio::sync::watch::channel(false);
let load_balancer = make_load_balancer();
// Start a load balancer on the tokio runtime ourselves
tasks.push(runtime.spawn(async move {
load_balancer.task()
.start(shutdown_rx.clone())
.await
}));
}
Starting a proxy service is also straightforward:
fn main() -> Result<(), anyhow::Error> {
// With no Server, we have to manage our own ServerConf
let server_config: Arc<ServerConf> = Arc::new(Default::default());
let mut proxy_service = http_proxy_service(&server_config, Proxy);
proxy_service.add_tcp("0.0.0.0:80");
// Start the http proxy on the tokio Runtime
tasks.push(runtime.spawn(async move {
proxy_service.start_service(None, shutdown_rx.clone(), 1)
.await
}));
}
Here’s an example where we start a new LoadBalancer service whenever we receive an event on a tokio signal (in this case,
a timer). This is the control loop running on main, that we use in place of Server#run_forever:
fn main() -> Result<(), anyhow::Error> {
let mut tasks = Vec::new();
let (shutdown_tx, shutdown_rx) = tokio::sync::watch::channel(false);
// Setup services, like above (load balancers, proxies, etc.)
// then proceed to main control loop.
runtime.block_on(async {
let mut interval = tokio::time::interval(Duration::from_secs(30));
loop {
tokio::select! {
// Wait for shutdown. Normally the Server handles all external signal handling for you.
_ = tokio::signal::ctrl_c() => {
tracing::info!("Got shutdown signal. Stopping");
// Trigger shutdown to all services
shutdown_tx.send(true)?;
// Join / wait for all tasks to stop
for task in tasks {
if let Err(err) = task.await {
tracing::error!("Join error during task shutdown: {:?}", err);
}
}
break;
}
// Contrived example: Making a LoadBalancer on a timer. In practice, you'd probably stash
// your LoadBalancer instances in a shared data structure, and start / stop them on whatever
// signal is meaningful for your service.
//
// This example uses a timer, but you can manage this any way you want.
_ = interval.tick() => {
tasks.push(runtime.spawn(async move {
make_load_balancer().task()
.start(shutdown_rx.clone())
.await;
}));
}
}
}
Ok(())
})
}
In real code, I run through a full reconciliation process inside the proxy process. The proxy calls
out to the control plane to fetch the list of configured load balancers, and starts / stops them when
they’re created or destroyed. This design allows me to host multiple LoadBalancer instances inside the same process, while still maintaining separate backend configurations for each distinct load balancer. The control tasks run on a separate tokio Runtime than the proxy and load balancer services that handle requests / responses.
Check out Pingora if you’re interested in a Rust based load balancer library.
I recently stood up a 42U server rack in my basement. Some people are into cars, I’m into servers. 😁

It’s a bit empty right now, but with plenty of room to expand for future projects! All the CAT6A
cables in my house terminate at the patch panel at the top of the rack, with a very basic router / switch
setup that plumbs it all together.
The thing I’m more excited about is the 3 node MINISFORUM UM750L mini PC cluster that I’ve started building on top of.

I’m programming a custom VM orchestration and control plane on the cluster called “lightbyte”. Currently, the system supports:
- Dynamically provisioning and placing Firecracker virtual machines on the worker nodes.
- Provisioning block storage volumes from rootfs images. These images are built via Nix, and automatically get deployed to the cluster during software updates.
- Scale groups, for dynamically scaling up multiple identical VMs. Sort of like EC2 autoscaling groups. Way overkill for a homelab, but why not?
- Rudimentary HTTP load balancer / proxy support via pingora. These can target scale groups or individual sets of VMs.
- Worker draining, to vacate all resources from a host node
Here I create a basic scale group with a configured rootfs image, then scale it up to 5 nodes.

Provisioning is all done via reconciliation controllers in the control plane server processes. Each resource
has its own separate controller that’s responsible for reconciliating desired resource state (stored across all 3
etcd nodes), against the current state of running resources on each worker.
Once VMs boot, they bridge to the physical network via a Linux bridge.

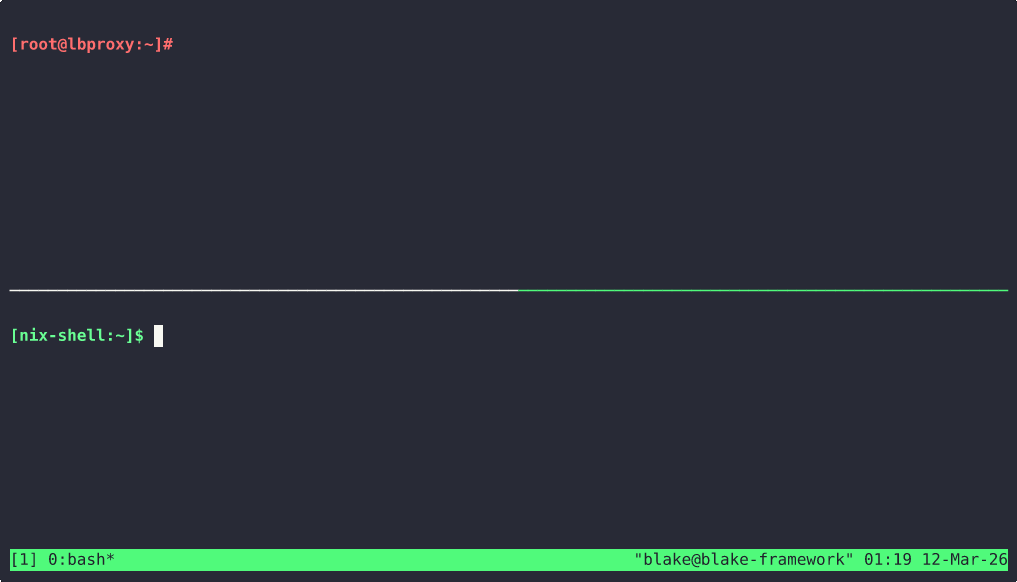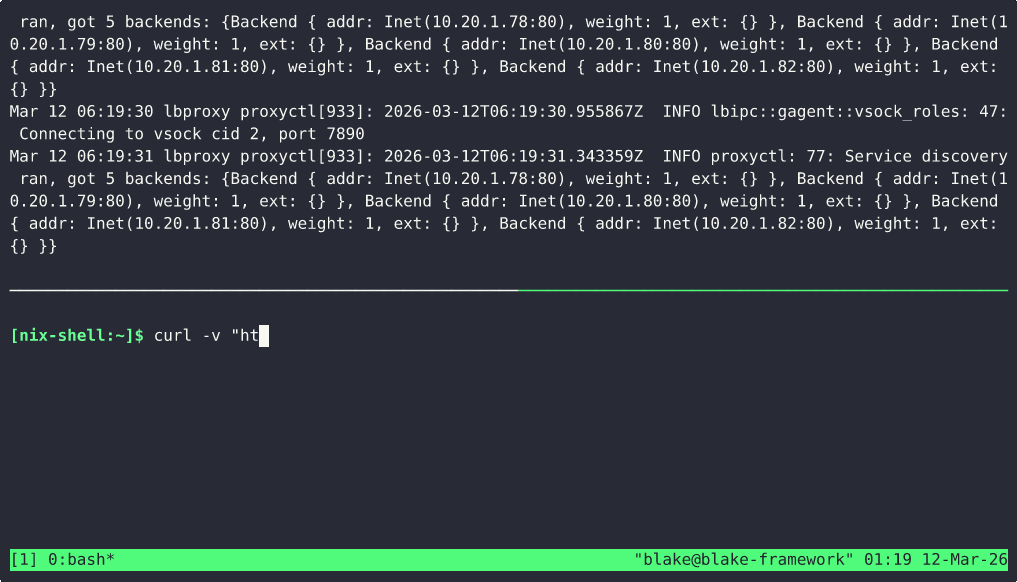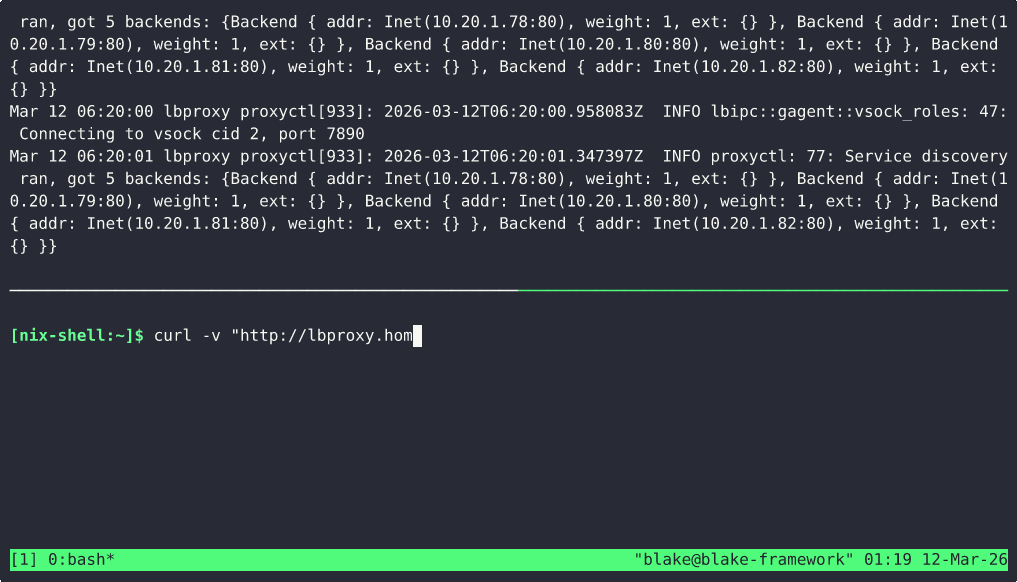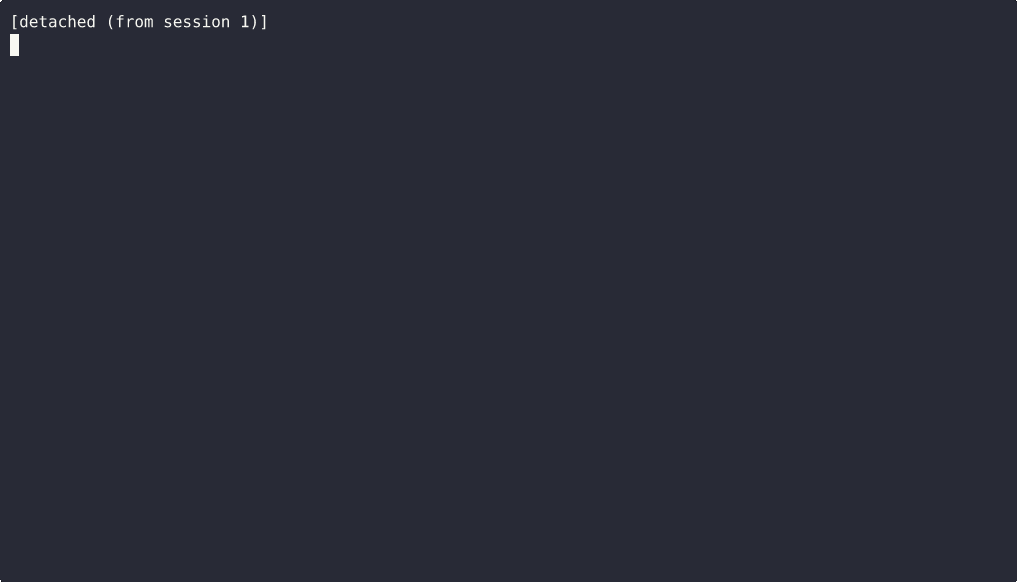
HTTP load balancers run inside guest VMs themselves, owned and managed by their own scale group. Once I implement DNS
in the cluster, my plan is to have DNS records that will round-robin across multiple proxy VMs, which themselves will proxy
to other underlying scale groups or collections of VMs. I dynamically push backend topology changes to the proxy guests
over a guest vsock socket server. This vsock socket allows the host machine to orchestrate the guest and push configuration changes without the guest needing to talk to the control plane directly.
Here are some of the software details:
- Implemented in Rust. Control plane, worker agents, guest agents, command line clients, etc.
- Control plane database is etcd, running on all 3 nodes, which stores all resource object state. I use etcd transactions to perform transactionally correct read-modify-write on the objects. Reconciliation controllers are leader-elected with etcd and executed on the control plane nodes. I use leader election to make sure there’s only 1 controller of each resource type running at a time.
- Workers all run NixOS. The entire system is deployed and updated with a single command via colmena.
- I’m using firecracker for the Vmm, which sits on top of Linux KVM for the hypervisor.
This has been a fun one to build. I’m looking forward to stabilizing things enough to use the system for all my
homelab services. It’s a little baby homelab cloud!